1.0 Project Overview
- Client Industry: Information Technology
- Objective: To develop a highly extensible, command-line interface (CLI) backup solution capable of managing unlimited databases across disparate engines with sophisticated lifecycle and retention policies.
2.0 Background
The client required a robust, automated backup utility capable of handling high-volume data across MySQL, ClickHouse, and MongoDB. The primary challenge was the need for a “future-proof” architecture—a tool that could not only scale to an unlimited number of hosts but also allow for the easy addition of new database engines and storage protocols without rewriting the core logic.
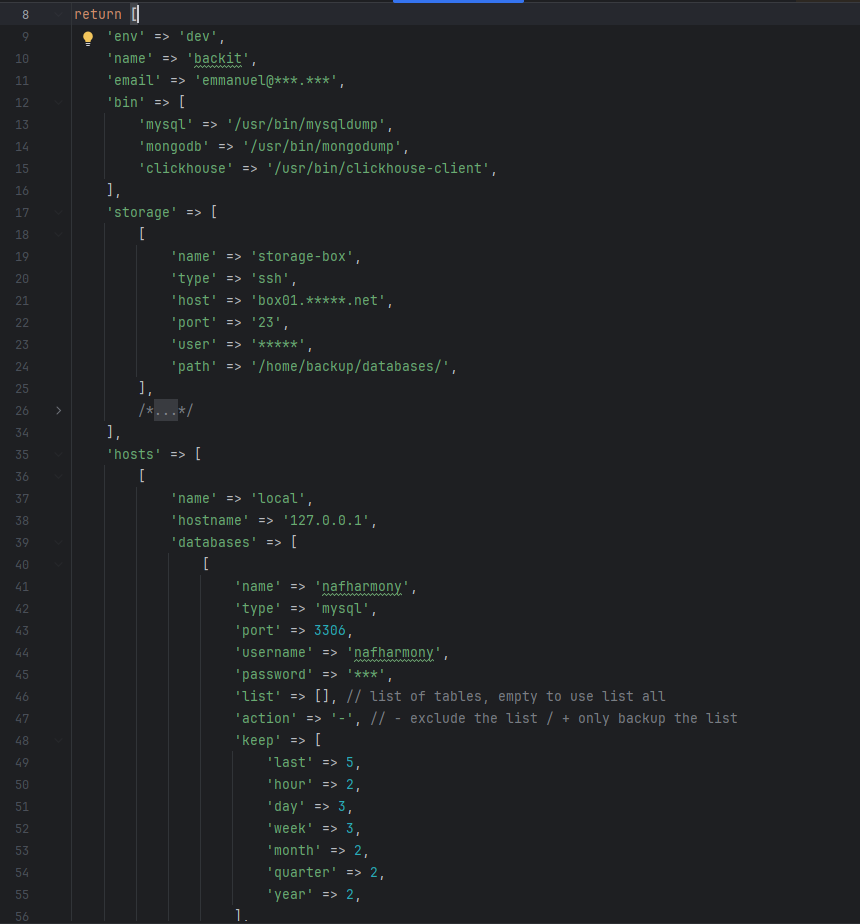
Furthermore, the solution needed to implement complex retention policies, allowing for granular control over how many daily, weekly, monthly, and yearly snapshots are preserved.
3.0 Project Scope
- Abstract Backup Framework: A core handler that standardizes the backup lifecycle, including file placement, naming conventions, and automated pruning.
- Modular Database Handlers: Dedicated drivers for different database types, decoupling the backup logic from the specific engine.
- Compression & Optimization: Integration of Gzip archiving to minimize storage footprints and reduce network bandwidth during transfers.
- Multi-Protocol Storage Layer: An abstract storage interface supporting diverse destinations:
- SFTP: Secure transmission via SSH.
- FTP: Standard remote file transfer.
- Local Filesystem: Direct storage on the host machine.
- Intelligent Pruning Engine: A rules-based system to automatically delete expired backups based on per-database configuration.
4.0 Technical Architecture
The system utilizes a Modular Architecture to ensure that processes remain decoupled and manageable.
| Component | Technology | Role |
|---|---|---|
| Logic & Flow Control | PHP | Manages configuration parsing, scheduling, and retention logic. |
| Execution Layer | Bash | Handles high-performance data dumping, archiving, and system-level operations. |
| Architecture | Event-Driven | Ensures asynchronous-style handling of backup states and logging. |
5.0 Core Features
- Universal Compatibility: Supports both local and remote databases and storage targets.
- Sophisticated Rotation: Implements time-based rotation, ensuring specific recovery points are available for days, weeks, months, or years.
- Unlimited Scalability: No software-defined limits on the number of hosts or databases processed.
- Storage Efficiency: Automated Gzip compression reduces the cost of offsite storage.
- Flexible Configuration: Per-database pruning rules allow different retention tiers for critical vs. non-critical data.
6.0 Key Benefits
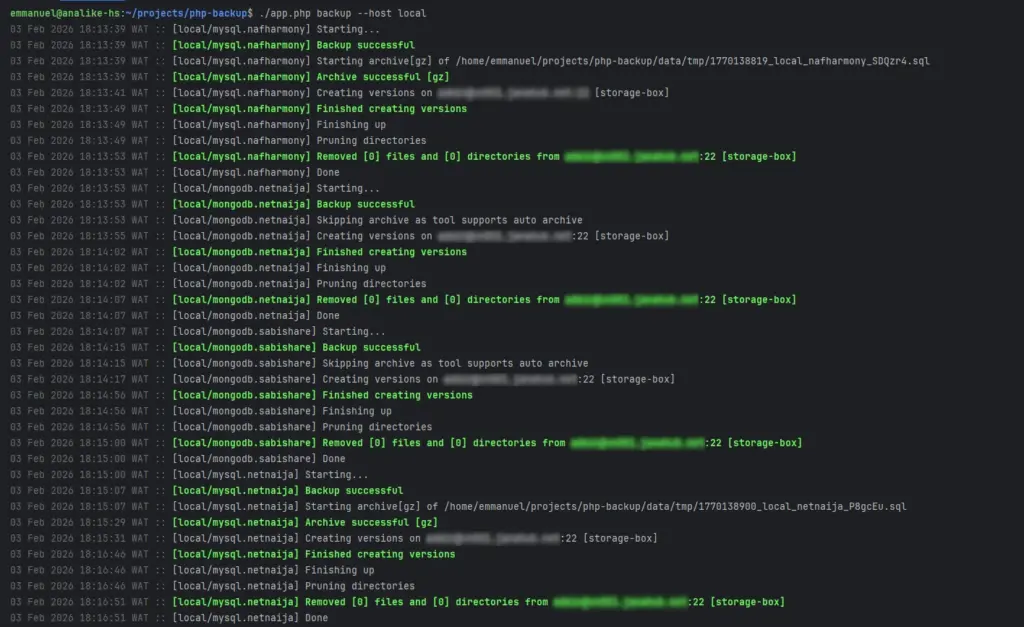
- Fault Tolerance: The system is designed so that a failure in one backup task does not interrupt the queue for others.
- High Concurrency: Supports multiple simultaneous instances, allowing for the parallel backup of large-scale database clusters.
- Offsite Redundancy: By supporting SFTP and FTP, the tool facilitates easy offsite disaster recovery (DR) compliance.
- Extensibility: The modular “Handler” design allows developers to add support for new databases (e.g., PostgreSQL or Redis) or storage backends (e.g., S3) in hours rather than days.
7.0 Conclusion
The backup utility was delivered on schedule and met all performance requirements. By providing a unified interface for disparate database types, the client significantly reduced the complexity of their infrastructure management. The system is currently in active production, providing reliable data protection and automated lifecycle management across the client’s entire IT estate.
8.0 Screenshots